Meta Launches LlamaFirewall to Bolster AI Cybersecurity
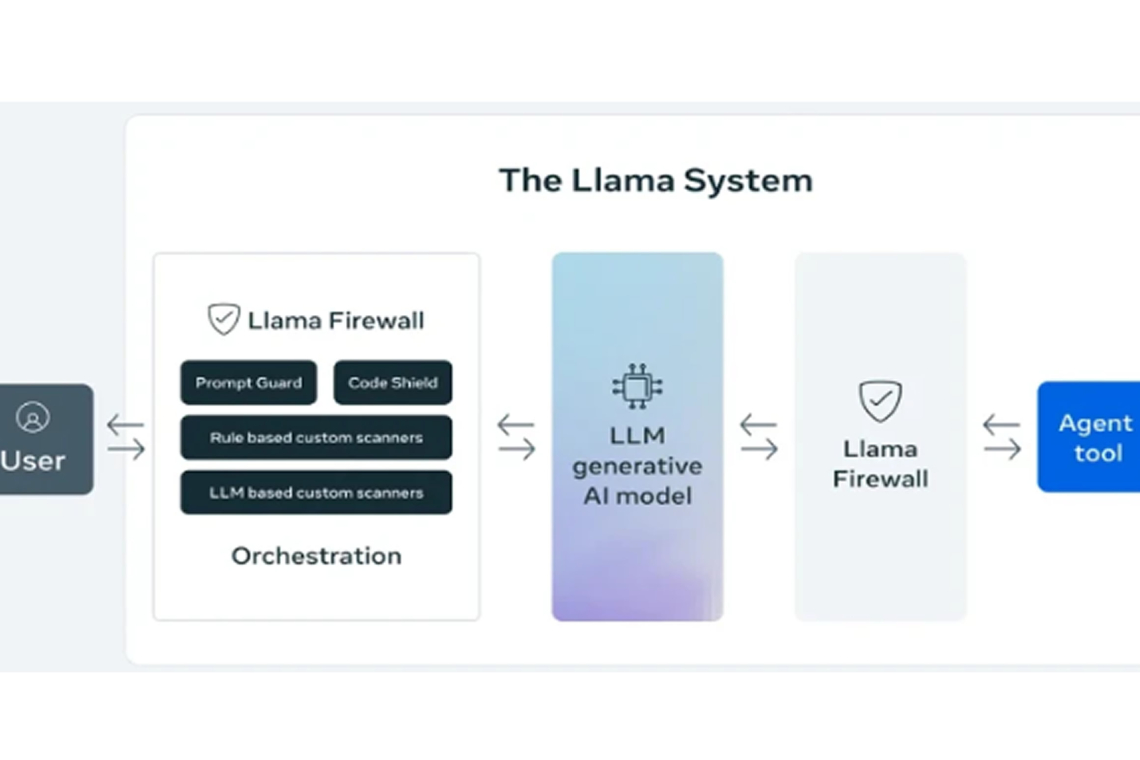
Meta has unveiled LlamaFirewall, an open-source security framework designed to protect AI systems against evolving cyber threats like prompt injection, jailbreaks, and insecure code execution.
The framework integrates three key security tools:
- PromptGuard 2: Detects real-time prompt injections and jailbreak attempts.
- Agent Alignment Checks: Analyzes AI agent reasoning to spot goal hijacking or indirect prompt manipulations.
- CodeShield: A static analysis tool that prevents AI from generating insecure code.
According to Meta, LlamaFirewall offers a modular architecture, enabling developers to build layered defenses across both simple LLM chat models and complex autonomous agents.
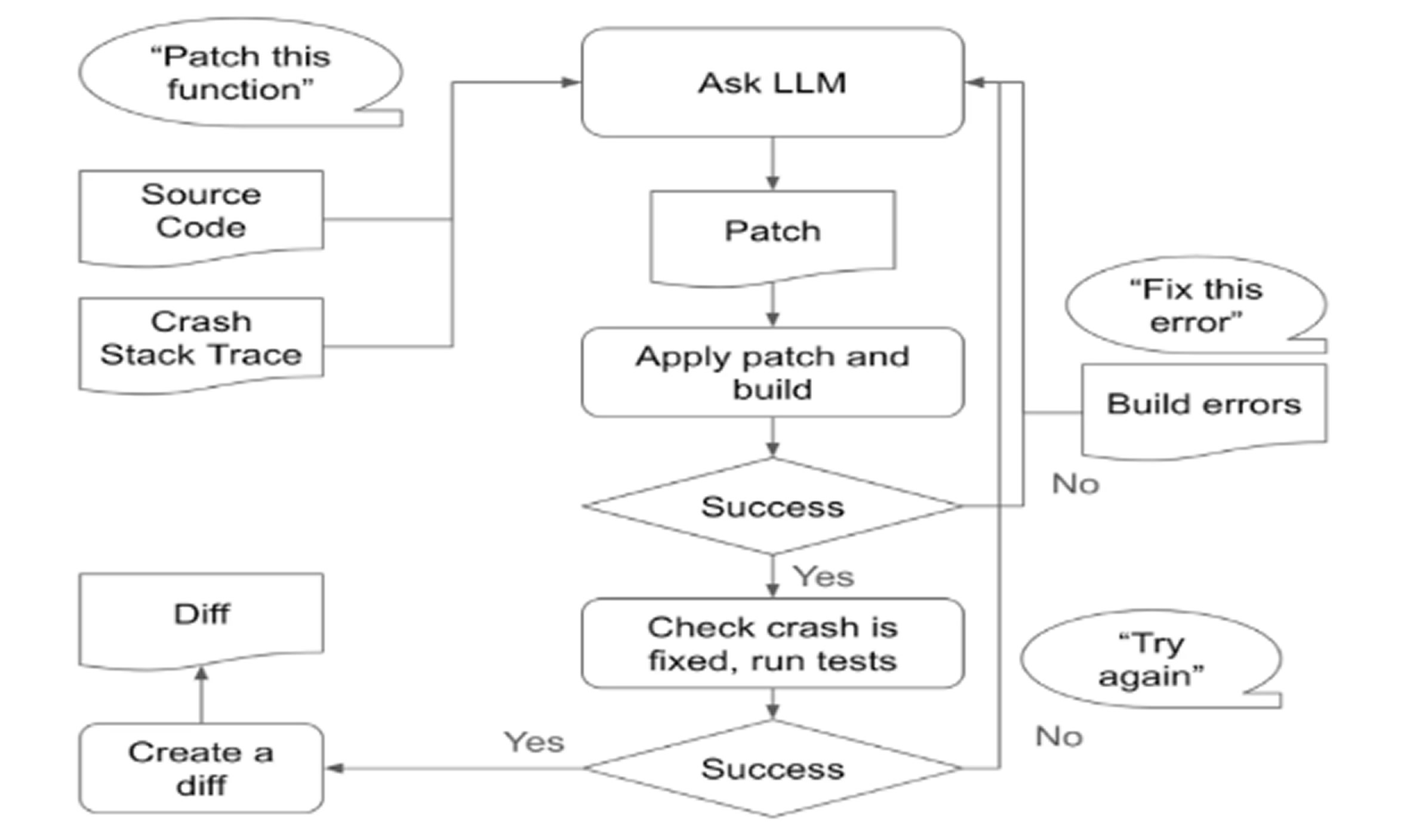
Additionally, Meta released updated versions of LlamaGuard and CyberSecEval, with the latter now including AutoPatchBench, a new benchmark for assessing an AI model’s ability to automatically patch C/C++ vulnerabilities found via fuzzing.
To further support secure AI adoption, Meta introduced Llama for Defenders, a program offering access to early and closed-source AI tools aimed at tackling specific security threats such as phishing and fraud.
These efforts align with Meta's broader privacy initiatives, including WhatsApp’s Private Processing feature—currently under testing—which promises secure, private AI functionalities through confidential computing.
Found this article interesting? Follow us on X(Twitter) ,Threads and FaceBook to read more exclusive content we post.