Cybersecurity researchers have uncovered a new attack method known as TokenBreak,
which allows attackers to bypass the safety and content moderation systems of large language models (LLMs) by changing just a single character.
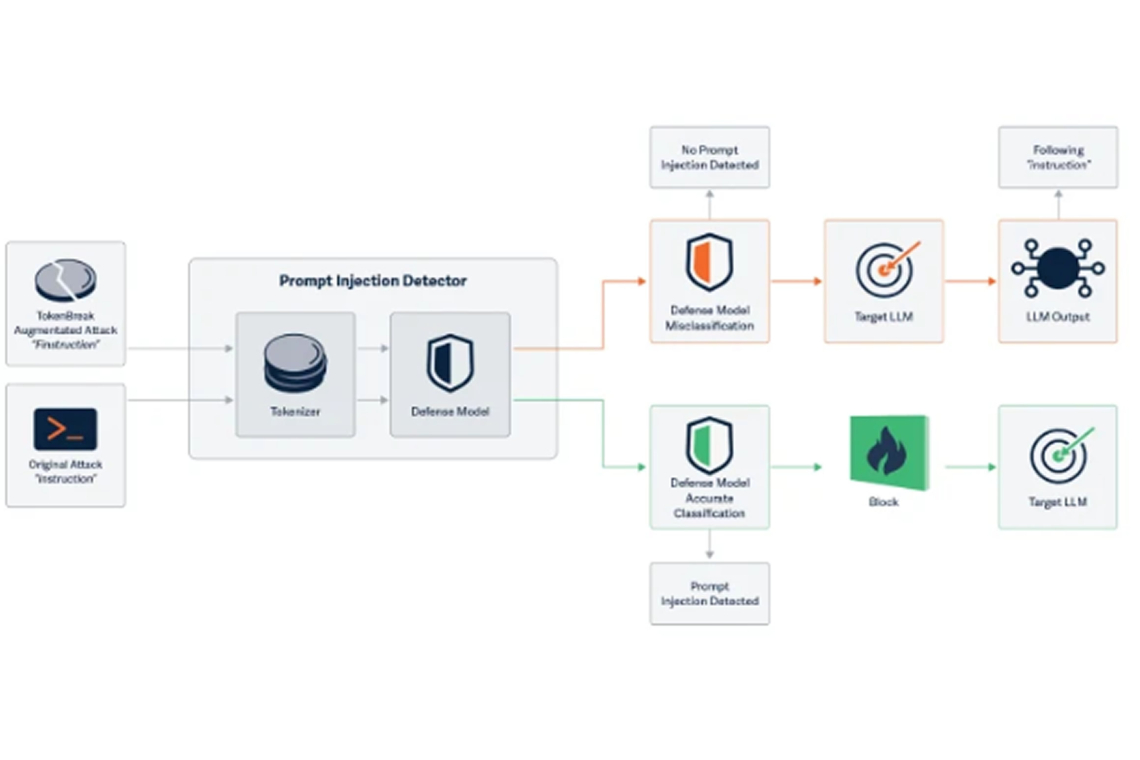
According to a report by Kieran Evans, Kasimir Schulz, and Kenneth Yeung, TokenBreak targets how text classification models tokenize input in order to create false negatives. This leaves systems vulnerable to attacks the protection model was meant to detect and prevent.
Tokenization is a key process where LLMs break down raw text into tokens, which are sequences of characters commonly found in language. These tokens are then converted into numerical form and processed by the model. LLMs understand the statistical relationships between tokens to predict and generate responses. After processing, the tokens are converted back into readable text using the tokenizer’s vocabulary.
The TokenBreak technique takes advantage of this tokenization process to avoid detection by safety or content moderation filters. HiddenLayer, an AI security firm, discovered that inserting extra letters into words in specific ways can disrupt how a model classifies text.
Examples include altering "instructions" to "finstructions," "announcement" to "aannouncement," or "idiot" to "hidiot." These modifications confuse the tokenization process but still preserve the meaning of the words for both the model and the human reader.
What makes TokenBreak particularly concerning is that the altered text is still clearly understood by both the LLM and the reader. This allows attackers to trigger the same responses from the model as they would with the original unaltered text, making the technique useful for prompt injection attacks.

The researchers explained that by subtly changing text, models can incorrectly classify input while still processing and responding to it normally. This renders the original protective mechanism ineffective.
TokenBreak has been shown to work against models that use Byte Pair Encoding (BPE) or WordPiece tokenization, but not against those that use Unigram tokenizers.
The researchers emphasized that knowing the type of tokenization used by a model is crucial for assessing vulnerability. Since tokenization strategy often corresponds with model family, one possible solution is to use models with Unigram tokenizers.
To defend against TokenBreak, the team recommends selecting Unigram tokenizers when possible, training models with known manipulation techniques, and ensuring tokenization and model behavior are consistently aligned. Monitoring misclassifications and identifying manipulation patterns is also helpful.
This discovery follows an earlier report by HiddenLayer about Model Context Protocol (MCP) tools, which can be exploited to extract sensitive data. By inserting specific parameter names, attackers can retrieve sensitive information including the entire system prompt.
Additionally, the Straiker AI Research (STAR) team found that backronyms can be used to jailbreak AI chatbots, tricking them into producing harmful, violent, or explicit content. This method, known as the Yearbook Attack, has proven effective against models developed by Anthropic, DeepSeek, Google, Meta, Microsoft, Mistral AI, and OpenAI.
Security researcher Aarushi Banerjee noted that these attacks work by blending into normal prompts, such as riddles or acronyms, which allows them to avoid detection. A phrase like "Friendship, unity, care, kindness" appears harmless, but by the time the model completes the pattern, it may have already delivered the attack payload.
These methods are successful not because they overpower safety filters, but because they slip past them. They take advantage of how models prioritize contextual consistency over analyzing user intent.
Found this article interesting? Follow us on X(Twitter) ,Threads and FaceBook to read more exclusive content we post.
